End-to-End Learning of Representations for Asynchronous Event-Based Data
Oct 27, 2019·
,
,
,
·
0 min read
Daniel Gehrig
Antonio Loquercio
Kosta G. Derpanis
Davide Scaramuzza
Abstract
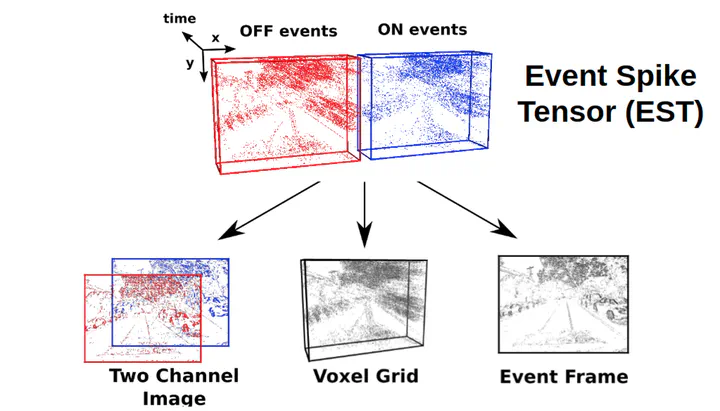
Event cameras are vision sensors that record asynchronous streams of per-pixel brightness changes, referred to as “events”. They have appealing advantages over frame-based cameras for computer vision, including high temporal resolution, high dynamic range, and no motion blur. Due to the sparse, non-uniform spatiotemporal layout of the event signal, pattern recognition algorithms typically aggregate events into a grid-based representation and subsequently process it by a standard vision pipeline, e.g., Convolutional Neural Network (CNN). In this work, we introduce a general framework to convert event streams into grid-based representations through a sequence of differentiable operations. Our framework comes with two main advantages: (i) allows learning the input event representation together with the task dedicated network in an end-to-end manner, and (ii) lays out a taxonomy that unifies the majority of extant event representations in the literature and identifies novel ones. Empirically, we show that our approach to learning the event representation end-to-end yields an improvement of approximately 12% on optical flow estimation and object recognition over state-of-the-art methods.
Type
Publication
Int. Conf. Comput. Vis. (ICCV)