End-to-End Learned Event- and Image-based Visual Odometry
Mar 20, 2024·
,
,
,
,
,
,
·
0 min read
Roberto Pellerito
Marco Cannici
Daniel Gehrig
Joris Belhadj
Olivier Dubois-Matra
Massimo Casasco
Davide Scaramuzza
Abstract
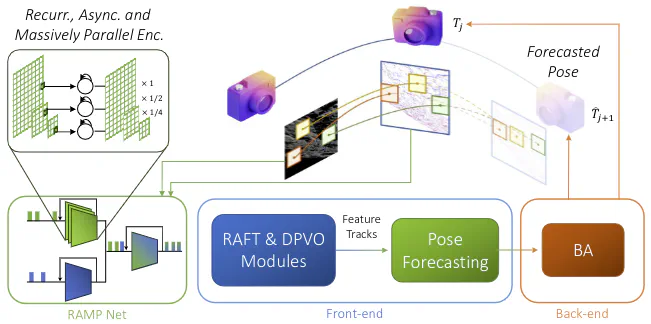
Visual Odometry (VO) is crucial for autonomous robotic navigation, especially in GPS-denied environments like planetary terrains. While standard RGB cameras struggle in low-light or high-speed motion, event-based cameras offer high dynamic range and low latency. However, seamlessly integrating asynchronous event data with synchronous frames remains challenging. We introduce RAMP-VO, the first end-to-end learned event- and image-based VO system. It leverages novel Recurrent, Asynchronous, and Massively Parallel (RAMP) encoders that are 8x faster and 20% more accurate than existing asynchronous encoders. RAMP-VO further employs a novel pose forecasting technique to predict future poses for initialization. Despite being trained only in simulation, RAMP-VO outperforms image- and event-based methods by 52% and 20%, respectively, on traditional, real-world benchmarks as well as newly introduced Apollo and Malapert landing sequences, paving the way for robust and asynchronous VO in space.
Type
Publication
arXiv